
Comparative Analysis: Transformer vs. RNN in Speech Applications
Comparative Analysis: Transformer vs. RNN in Speech Applications
Abstract
This paper provides an extensive comparison between Transformer and Recurrent Neural Networks (RNN) across a wide range of speech tasks: automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). Surprisingly, Transformer outperforms RNN in 13 out of 15 ASR benchmarks, and performs comparably in ST and TTS tasks. In addition to accuracy, the paper shares valuable training tips and reports that Transformer often benefits more from larger mini-batches and multiple GPUs. All experiments are integrated into ESPnet with reproducible recipes.
1. Motivation: Why compare Transformer and RNN?
Transformer has revolutionized NLP, but its application to speech tasks remained underexplored due to its computational complexity and training sensitivity.
RNNs, especially LSTMs, have long been the go-to choice for sequential speech processing due to their natural alignment with time-series data.
This paper seeks to:
- Quantify how much Transformer improves accuracy in ASR, ST, and TTS.
- Share practical training tricks.
- Provide reproducible recipes in ESPnet.
2. Architecture Overview
🔁 Recurrent Neural Networks (RNN)
- Encoder: Bi-directional LSTM (BLSTM)
- Decoder: Uni-directional LSTM with attention
- Natural for temporal data but inherently sequential, making parallelism difficult
🔀 Transformer
- Relies on self-attention instead of recurrence
- Supports full parallelization in both encoder and decoder
- Requires positional encoding to retain time structure
📝 Both models share a sequence-to-sequence (S2S) structure:
EncPre → EncBody → DecPre → DecBody → DecPost
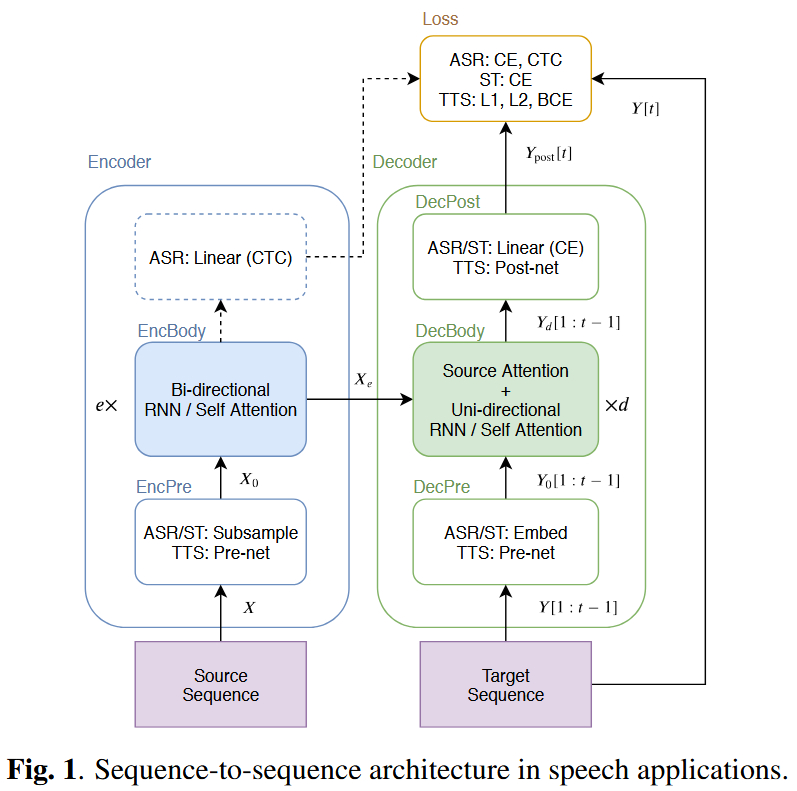
3. Application to Speech Tasks
🗣️ ASR (Automatic Speech Recognition)
Input: log-mel features with pitch features (83-dim) [1]
Loss: Weighted sum of S2S and CTC losses
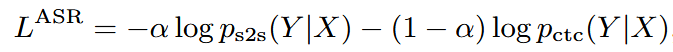
Decoding combines S2S, CTC, and optionally RNN-LM
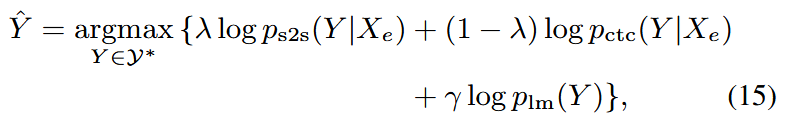
🌐 ST (Speech Translation)
- Input: speech in one language
- Output: translated text in another
- Same structure as ASR but without CTC due to non-monotonic alignment
🗣️→📊 TTS (Text-to-Speech)
- Input: Text sequence
- Output: Mel-spectrogram sequence + EOS probability
- Loss: Combination of L1 loss and binary cross-entropy (BCE)
Training uses teacher-forcing; inference is autoregressive.
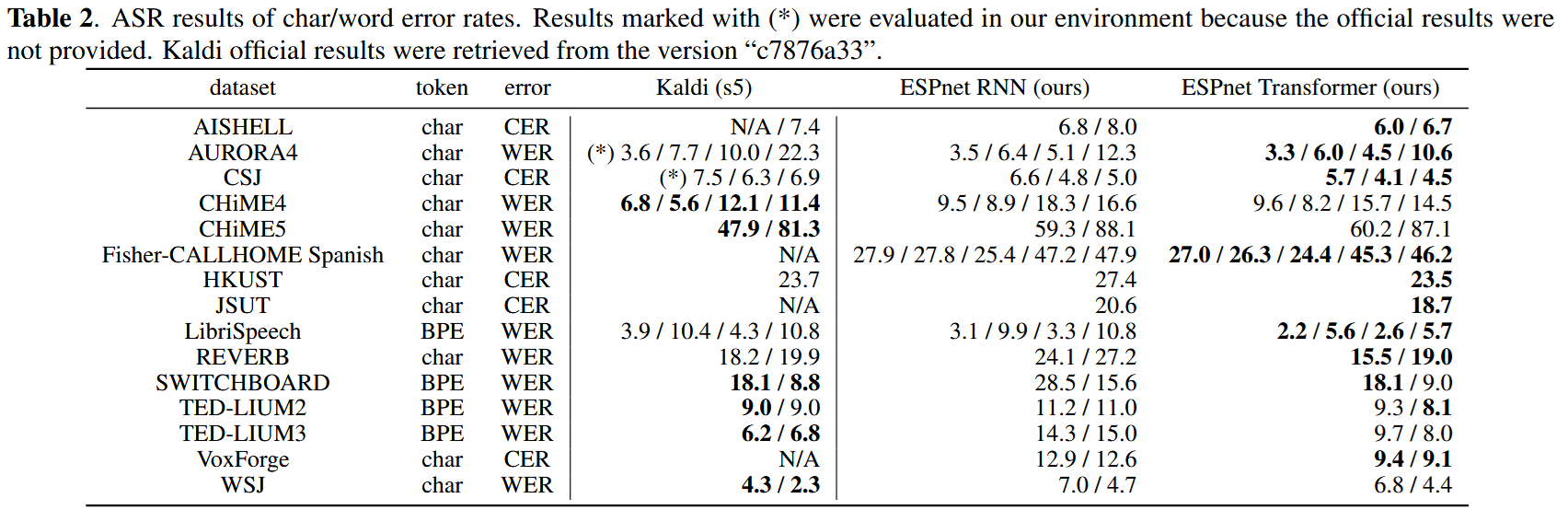
4. ASR: Experimental Results
✅ Benchmarks on 15 ASR tasks
- Languages: English, Japanese, Chinese, Spanish, Italian
- Conditions: clean, noisy, far-field, low-resource
- Transformer outperformed RNN on 13 out of 15 corpora
- Even without a pronunciation dictionary or alignment, Transformer matches or surpasses Kaldi in many tasks
🔧 Training Tips
- Transformer benefits greatly from large minibatches
- Accumulating gradients helps when GPUs are limited
- Dropout is essential for Transformer
- SpecAugment and speed perturbation improve both models
- Same decoding hyperparameters (CTC/LM weight) can be reused
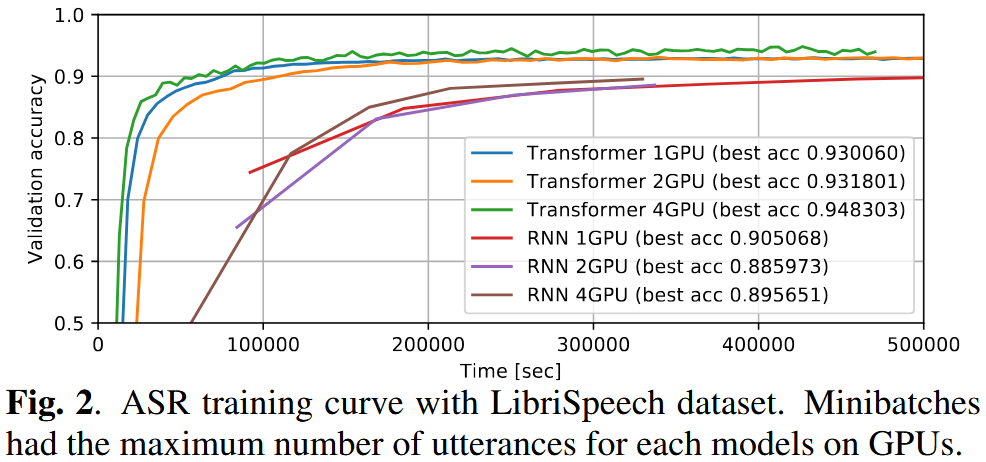
5. Multilingual ASR
- Single model trained on 10 languages (e.g., English, Japanese, Spanish, Mandarin)
- Output units: shared grapheme vocabulary (5,297 symbols)
- Transformer shows strong language-agnostic performance
- Achieved >10% relative improvement in 8 languages
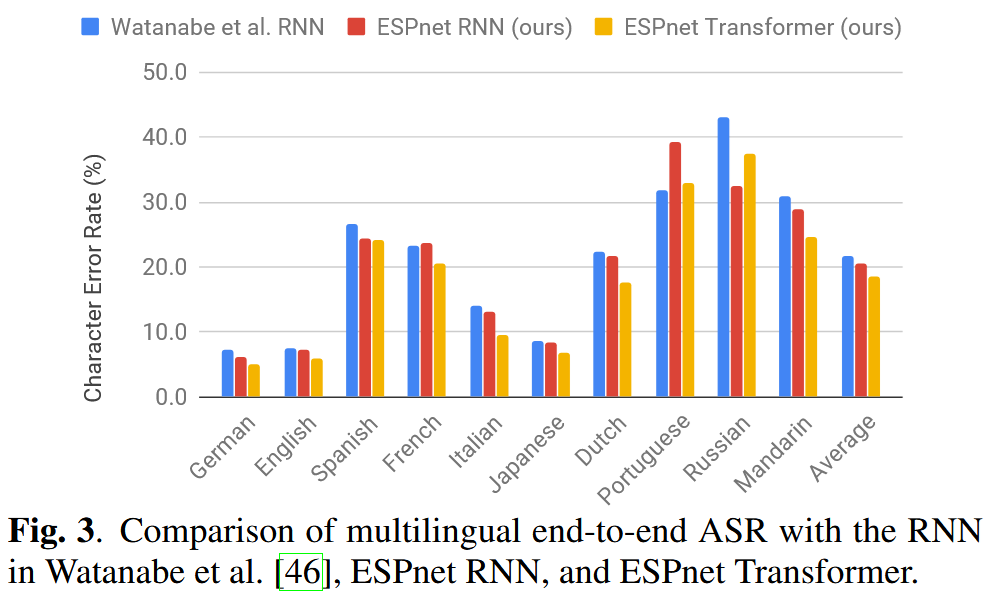
6. Speech Translation (ST)
- Dataset: Fisher–CallHome (English–Spanish)
- Transformer BLEU: 17.2 (vs RNN: 16.5)
- Reused encoder from ASR to alleviate underfitting
- Transformer still requires careful training on low-resource ST tasks
7. Text-to-Speech (TTS)
- Compared on M-AILABS (Italian) and LJSpeech (English)
- Validation loss (L1) is comparable between models
- Transformer learns better with large batches
- Guided attention loss selectively applied to a few attention heads
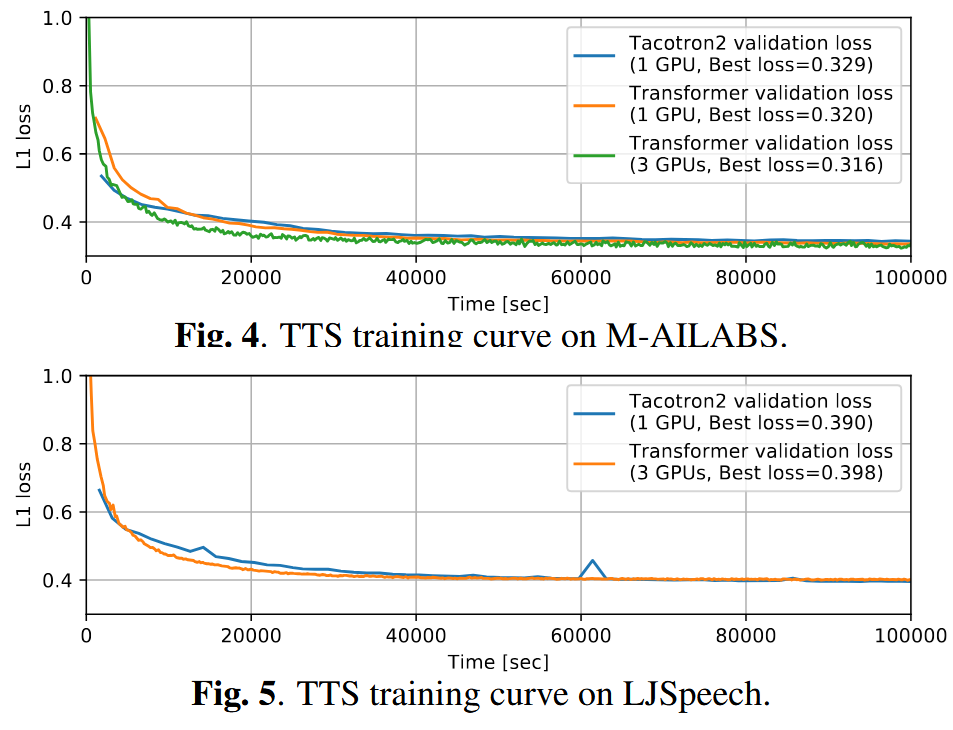
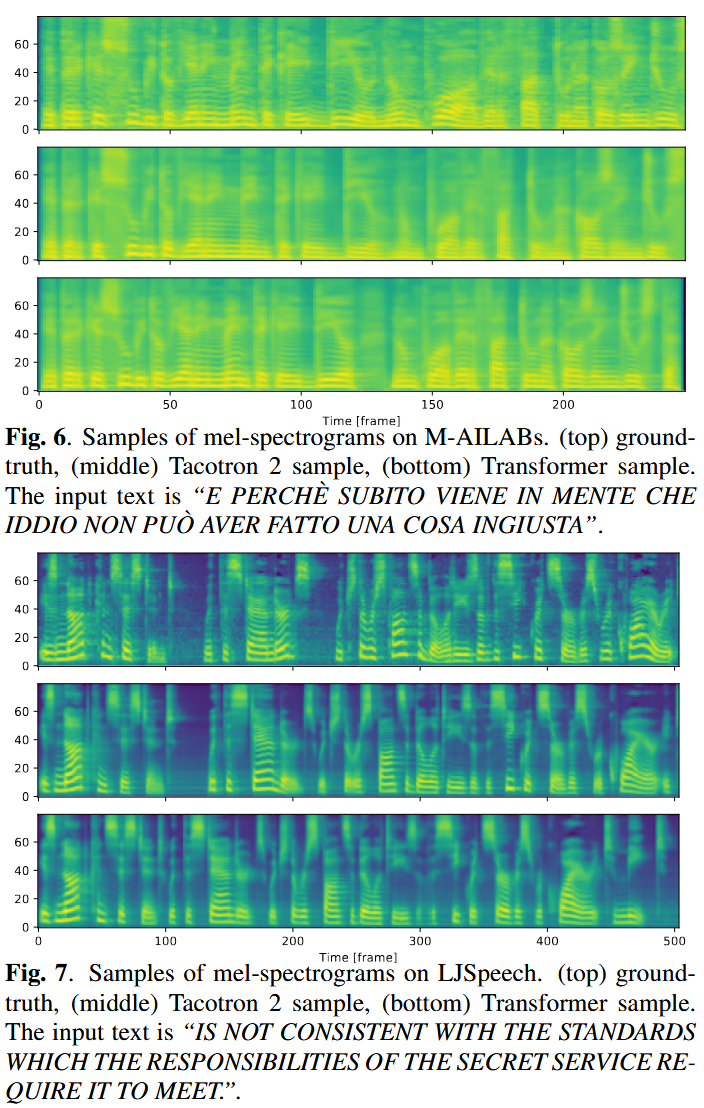
⚠️ Transformer TTS Challenges
- Decoding is significantly slower than RNN
- FastSpeech reduces latency (0.6 ms/frame vs 78 ms with Transformer)
8. Conclusion
Transformer brings:
✅ Better accuracy ✅ Easier scaling with multiple GPUs ✅ Reproducible and open recipes (via ESPnet)
But...
⚠️ Needs careful training ⚠️ Inference can be slower, especially in TTS
Nonetheless, this work strongly positions Transformer as a preferred architecture for end-to-end speech tasks.
9. Resources
- GitHub: ESPnet Toolkit
- Audio samples & TTS demos: bit.ly/329gif5
- P. Ghahremani, B. BabaAli, D. Povey, K. Riedhammer, J.Trmal, and S. Khudanpur, “A pitch extraction algorithm tuned for automatic speech recognition,” in ICASSP, 2014, pp. 2494–2498.
📌 Citation
If you find this useful, please cite:
@INPROCEEDINGS{9003750,
author={Karita, Shigeki and Chen, Nanxin and Hayashi, Tomoki and Hori, Takaaki and Inaguma, Hirofumi and Jiang, Ziyan and Someki, Masao and Soplin, Nelson Enrique Yalta and Yamamoto, Ryuichi and Wang, Xiaofei and Watanabe, Shinji and Yoshimura, Takenori and Zhang, Wangyou},
booktitle={2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)},
title={A Comparative Study on Transformer vs RNN in Speech Applications},
year={2019},
pages={449-456},
keywords={Decoding;Training;Task analysis;Xenon;Recurrent neural networks;Speech recognition;Transforms;Transformer;Recurrent Neural Networks;Speech Recognition;Text-to-Speech;Speech Translation},
doi={10.1109/ASRU46091.2019.9003750}
}