
Context-Aware Dynamic Pruning for Speech Foundation Models
Context-Aware Dynamic Pruning for Speech Foundation Models
arXiv/ICLR 2025 Accepted Paper
Abstract
本研究は、マルチタスク・マルチリンガルな音声基盤モデルに対して、コンテキストに応じた動的プルーニングを提案。これにより、推論時の計算コストを最大約30%削減しつつ、精度を維持することに成功した。従来のプルーニングが訓練時固定であるのに対し、本手法では言語・話者・タスクなどの文脈に応じて、モジュールレベルでの柔軟な構造最適化を行う。
1. Motivation: なぜ動的プルーニング?
- 従来のLLMや音声モデルは巨大で、推論コストが実用上の障壁に。
- 音声タスクは時系列長が長く、特にデコーダ側の計算量が大きい。
- しかし、全てのモジュールが常に必要とは限らない。
本研究は、
- タスクや言語ごとに「必要な構造は異なる」という仮説のもと、
- 文脈に応じて最適構造を選ぶ動的プルーニングを提案する。
2. Architecture Overview
🧠 ベースモデル: Open Whisper-Style Speech Models (OWSM v3.1)
- エンコーダ: E-Branchformer (Self-Attention + cgMLP)
- デコーダ: TransformerDecoder
- コンテキスト(言語・タスク)埋め込みを入力に追加
🧩 プルーニング単位:
- Encoder: FFN1, glob-ATT, cgMLP, FFN2
- Decoder: Self-ATT, Src-ATT, FFN
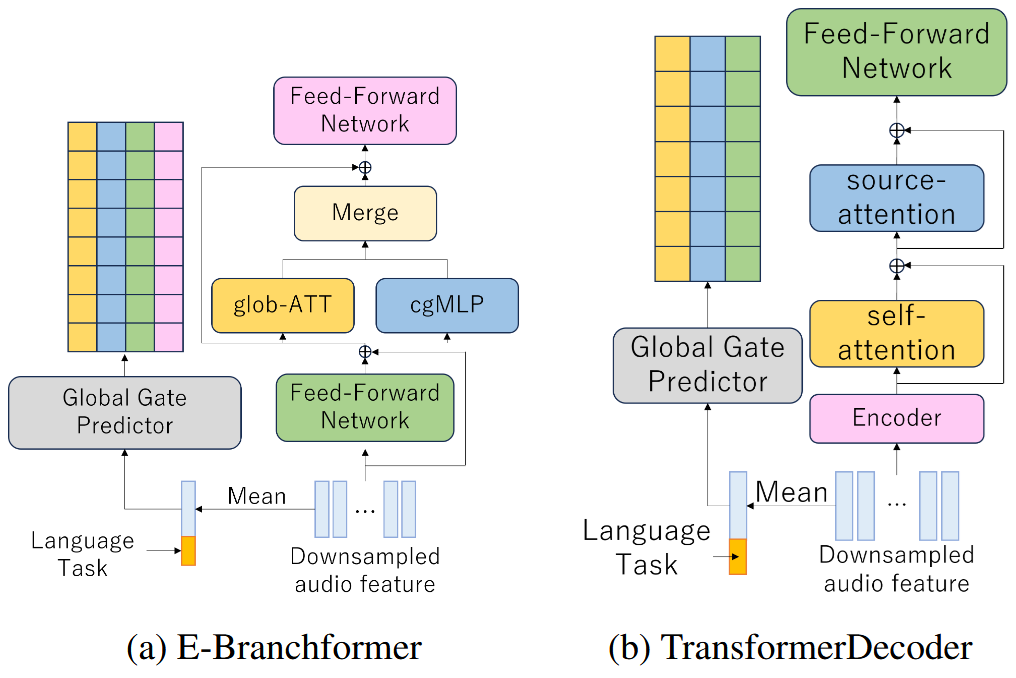
3. Proposed Method: Context-Aware Dynamic Pruning
🎛️ モジュールごとのGate制御
- 各層・各モジュールに対して、**「使うかどうか」**のバイナリマスクを学習。
- Gumbel-Softmax + SGSEによりバイナリ化しつつ、勾配伝播可能に。
📐 損失関数 = モデル損失 + スパース性ペナルティ 
スパース性のペナルティは2乗の項を入れています。 単純に差分をとるだけだと狙ったsparsityにならないのですが、2乗の項いれるとかなり効きました。
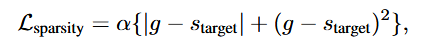
ここで、alphaは定数、$s_{target}$ は狙ったsparsity, gはencoder/decoderのsparsityの平均値です。
4. Experiments
📊 データセット
- Europarl-ST (独・仏・伊、各20時間程度)
- タスク: ASR (音声認識), ST (音声翻訳)
🧪 実験条件
- プルーニング率(sparsity target): 10%〜90%
- エンコーダ/デコーダ/両方を別々に評価
- 評価指標: ASR = WER, ST = BLEU
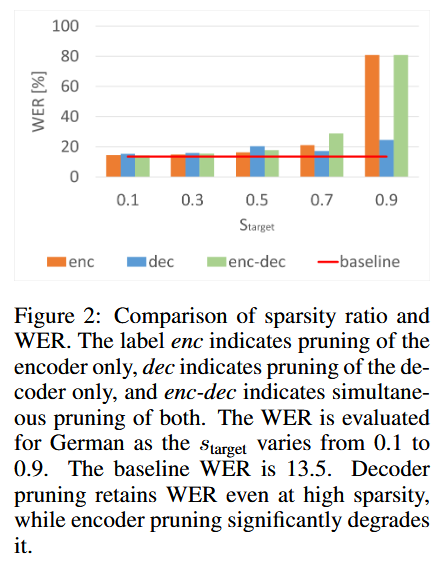
5. ASR Results
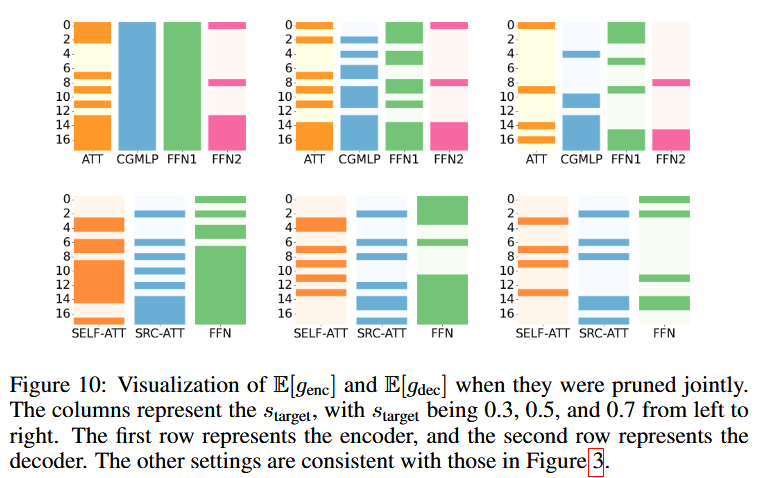
- 高スパース化(70%以上)では、エンコーダ側をプルーニングすると精度低下。
- 特にcgMLPの重要性が顕著(削るとWER悪化)。
- 一方で、デコーダ側のプルーニングは高スパースでも影響小。
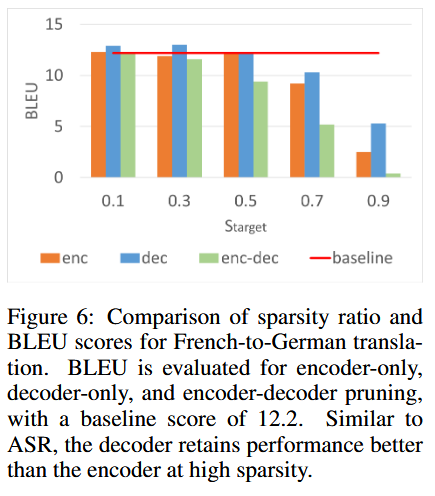
6. ST Results
- STではデコーダのFFNやSelf-Attentionが重要。
- エンコーダはASRと同様にcgMLPが主要。
- ASRと比較して、デコーダの構造がSTでより重要であることを確認。
- Source attentionはモデルの後半でactivateされる。これはASRでもSTでも、Decoderだけをpruningした際にほぼ確定で現れた
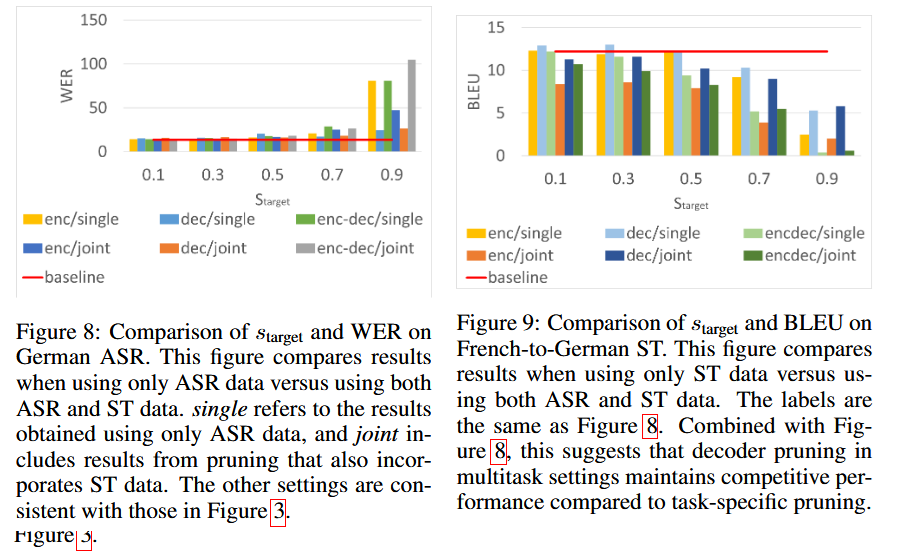
7. Multi-task Joint Training
- ASRとSTを同一モデルで同時訓練
- 推論時にはエンコーダよりもデコーダのプルーニングが有効
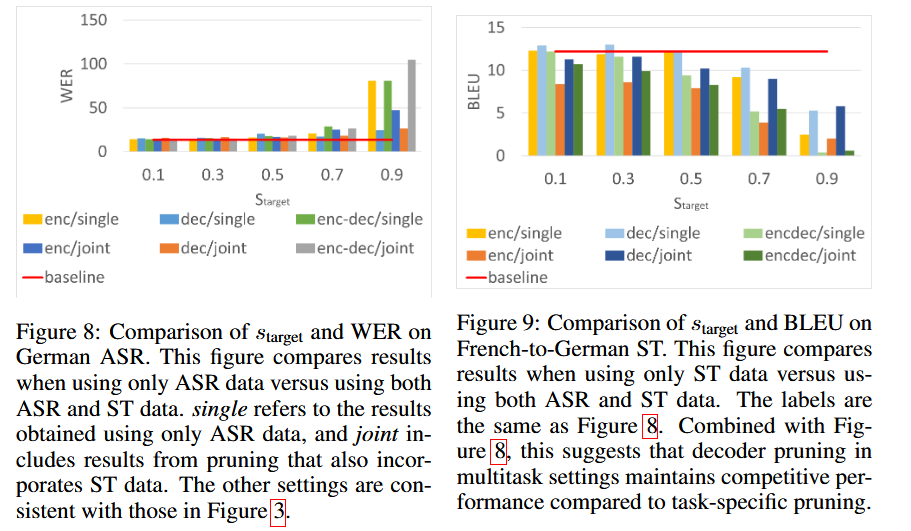
8. Inference Efficiency
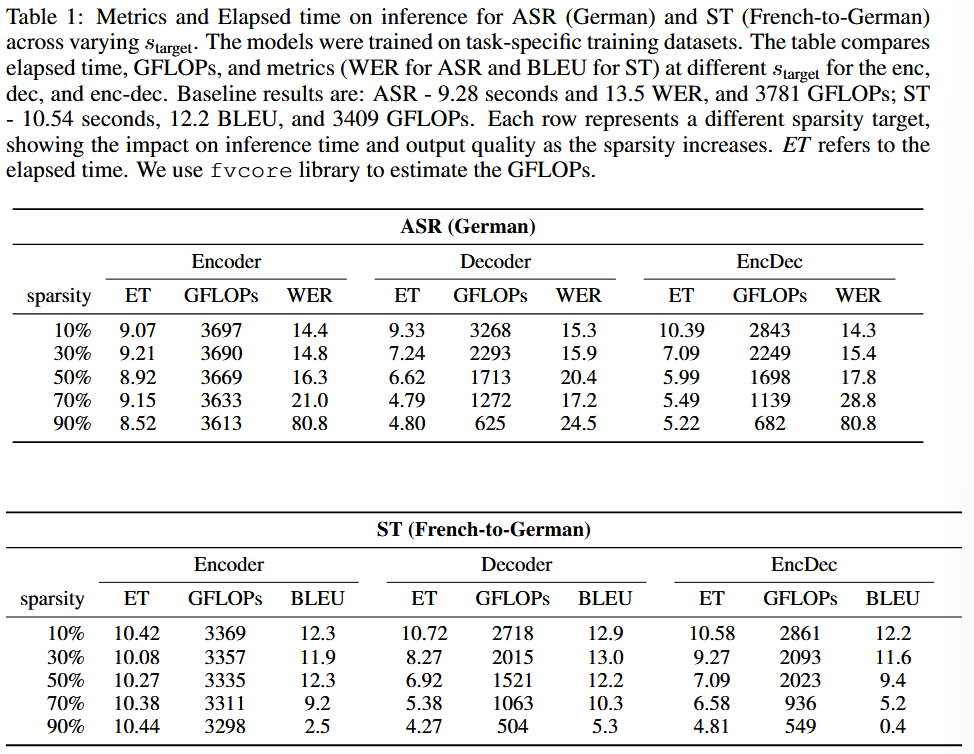
⏱️ スピード vs. 精度
デコーダの50%プルーニングで:
- ASR: 28.6% 時間短縮、2.8% WER上昇
- ST: 34.3% 時間短縮、BLEU維持
9. Conclusion
✅ タスク・言語に応じた動的構造最適化が可能 ✅ プルーニングによって推論時間を大幅短縮しつつ精度を保持 ⚠️ 特にcgMLP(局所情報)とデコーダ構造はタスク依存で重要
🔧 ESPnet + HuggingFace で再現可能なレシピを提供
10. Citation
@inproceedings{
someki2025contextaware,
title={Context-aware Dynamic Pruning for Speech Foundation Models},
author={Masao Someki and Yifan Peng and Siddhant Arora and Markus M{\"u}ller and Athanasios Mouchtaris and Grant Strimel and Jing Liu and Shinji Watanabe},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=u2QdCiOgwA}
}おまけ
修士はいってまさか1か月で書くことになるとは思っていませんでした。 なかなか大変でしたし正直通るかどうかかなり不安でしたが、先生にかなりサポートしていただいて何とかなりました。
Introduction, related works等かなり手を入れていただいたので、今後はなるべく直接手を加えてもらう修正がなくなるように初手draftを書けるように頑張りたいですね 実験の数も多く、直前はGPUを大量に占拠させてもらって何とかなりました。 いろいろと反省の残るprojectだったなと思います