ESPnet3 Data Preparation With Providers And Runners
ESPnet3 Data Preparation With Providers And Runners
The same provider/runner infrastructure can be used for dataset preparation.
This is useful when a recipe needs work such as:
- downloading many source files
- unpacking or normalizing raw data
- building manifests
- computing derived metadata in parallel
The idea is the same as inference:
- the provider builds shared runtime objects
- the runner processes indices
- shard outputs are merged at the end
Where this fits in ESPnet3
Recipe-local dataset code usually lives under:
egs3/<recipe>/<system>/dataset/
builder.py
dataset.py
config.yaml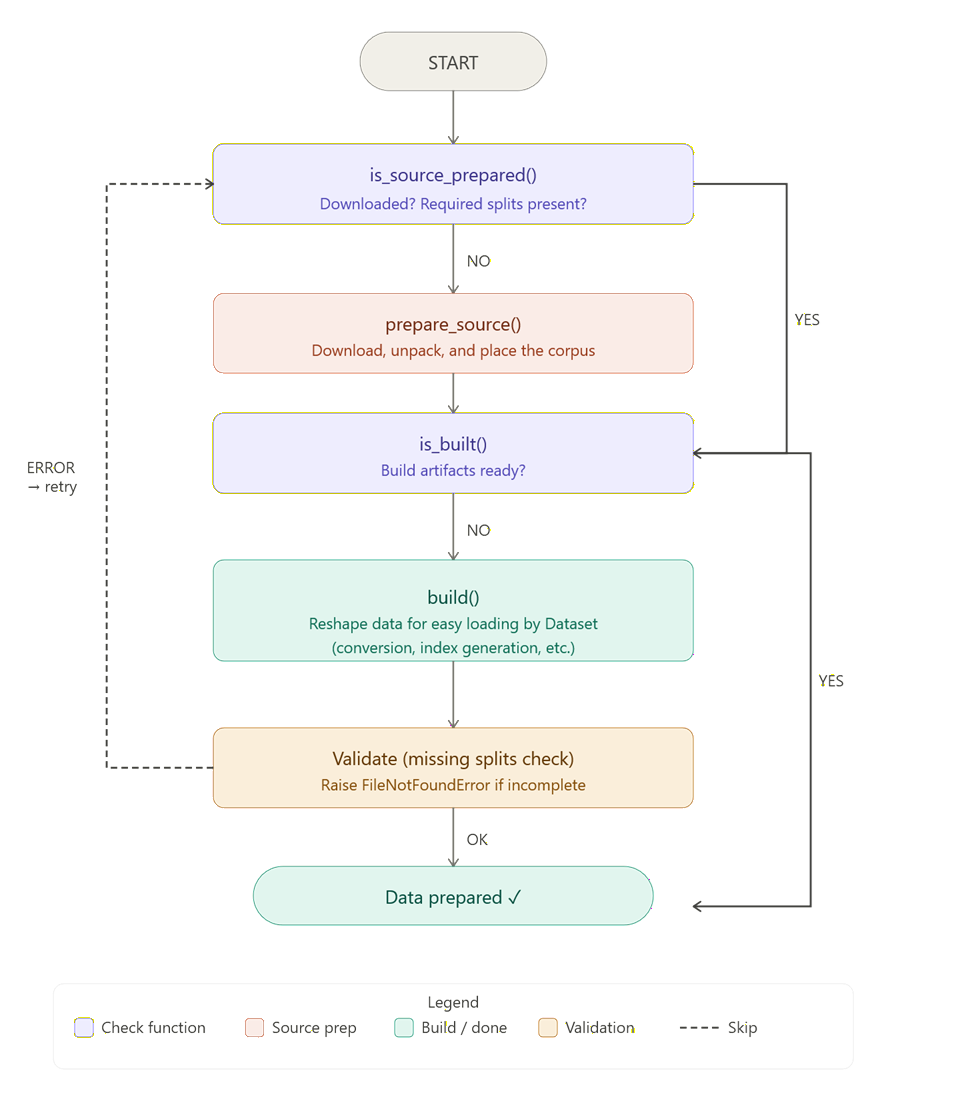
That layer is usually driven by DatasetBuilder:
See:
egs3/mini_an4/asr/dataset/builder.pyegs3/librispeech_100/asr/dataset/builder.py
For simple recipes, build() can stay single-process. For heavier recipes, the expensive part can use a provider/runner pair.
Two levels of preparation
It helps to separate two kinds of work:
- Builder lifecycle
This is the coarse recipe lifecycle:
- download or validate source data
- extract archives
- create final manifests
Example:
MiniAn4Builder.prepare_source()extracts the archiveMiniAn4Builder.build()converts audio and writes TSV manifestsLibriSpeech100Builder.prepare_source()only validates the source tree
- Parallel inner loop
This is the fine-grained loop inside one expensive step:
- process one utterance
- download one asset
- normalize one transcript
- compute one metadata record
That inner loop is where EnvironmentProvider and BaseRunner fit.
Real ESPnet3 example: collect-stats
The closest in-tree example today is not a dataset download stage. It is collect_stats.
Implementation:
espnet3/components/data/collect_stats.pyCollectStatsInferenceProviderCollectStatsRunner
That code uses the same pattern:
- provider builds dataset, collate function, model, and device
- runner processes one batch or shard
- reducer hooks write shard files and merge them later
If you want to design a heavy dataset-preparation stage, this is the best reference in the current codebase.
Pattern for dataset preparation
Use this pattern when your recipe has many independent items to process.
The provider builds shared state once. The runner handles one item at a time.
Example: parallel download preparation
Imagine a recipe-local package like:
egs3/falar/asr/dataset/
builder.py
download_parallel.pyThe builder can stay responsible for lifecycle checks:
from espnet3.components.data.dataset_builder import DatasetBuilder
class FalarBuilder(DatasetBuilder):
def is_source_prepared(self, recipe_dir, **kwargs):
...
def prepare_source(self, recipe_dir, **kwargs):
...
def is_built(self, recipe_dir, **kwargs):
...
def build(self, recipe_dir, **kwargs):
# This is where a provider/runner pair can be used.
...Then the expensive per-item work can move into a parallel helper module.
Example: parallel download fan-out
This is the pattern you want when one dataset has many independent URLs.
class DownloadProvider(EnvironmentProvider):
def build_env_local(self):
return {
"items": load_download_plan(self.config.plan_path),
"downloads_dir": Path(self.config.downloads_dir),
}
def build_worker_setup_fn(self):
plan_path = self.config.plan_path
downloads_dir = Path(self.config.downloads_dir)
def setup():
return {
"items": load_download_plan(plan_path),
"downloads_dir": downloads_dir,
}
return setup
class DownloadRunner(BaseRunner):
@staticmethod
def forward(idx, items, downloads_dir, **env):
item = items[idx]
target = downloads_dir / item["relative_path"]
target.parent.mkdir(parents=True, exist_ok=True)
download_one_file(item["url"], target)
return {"path": str(target), "status": "ok"}This keeps the download logic parallel-ready without forcing the builder itself to know anything about Dask.
Relation to existing recipe code
Current recipe examples show the builder side clearly:
MiniAn4Builder.build()converts SPH to WAV and writes manifestsLibriSpeech100Buildervalidates a raw directory-backed recipe
Current core examples show the parallel side clearly:
So a heavier dataset-preparation recipe usually combines those two ideas:
builder.pyowns lifecycle checks- a provider/runner helper owns the parallel inner loop
Output writing
Do not expect return {"path": ...} from forward() to create files.
The default path is only an in-memory shard state:
forward(idx)
-> result
-> BaseRunner.write_record(...)
-> state["records"].append(result)
-> BaseRunner.merge(...)
-> NoneThat means no SCP, TSV, or JSONL is written unless your runner writes it.
For real files, override the reducer hooks:
class DownloadRunner(BaseRunner):
@staticmethod
def forward(idx, items, downloads_dir, **env):
item = items[idx]
target = downloads_dir / item["relative_path"]
target.parent.mkdir(parents=True, exist_ok=True)
download_one_file(item["url"], target)
return {"path": str(target), "status": "ok"}
@staticmethod
def open_writers(shard_dir, **env):
return {
"manifest": (shard_dir / "downloads.tsv").open("w", encoding="utf-8"),
}
@staticmethod
def write_record(writers, result, state, **env):
writers["manifest"].write(f'{result["path"]}\t{result["status"]}\n')
@staticmethod
def close_writers(writers):
writers["manifest"].close()
def merge(self, shard_dirs):
out_path = self.output_dir / "downloads.tsv"
with out_path.open("w", encoding="utf-8") as out_f:
for shard_dir in sorted(shard_dirs):
part = shard_dir / "downloads.tsv"
if part.exists():
out_f.write(part.read_text(encoding="utf-8"))
return {"manifest": str(out_path)}The output then looks like:
downloads/
manifest.json
split.0/
downloads.tsv
done
split.1/
downloads.tsv
done
downloads.tsvInferenceRunner is just a specialized version of this pattern:
InferenceRunner.write_record(...)
-> split.N/hyp.scp
-> split.N/ref.scp
InferenceRunner.merge(...)
-> hyp.scp
-> ref.scpFor durable preparation outputs, use BaseRunner reducer hooks such as:
That is the pattern used by CollectStatsRunner. It is better when shard outputs are too large to keep in memory.
Common mistakes
- Putting heavy mutable state directly into the runner
- Doing all file writes inside
build()with no per-item split - Returning huge in-memory blobs instead of writing shard outputs
- Re-reading the full source manifest inside every
forward()call - Using provider/runner for a tiny one-shot shell task
Related pages
Provider / Runner
Read the base contract for env construction and static compute.
Inference Provider
See the stage-facing dataset/model provider used during inference.
Datasets
Read how recipe-local dataset code plugs into DataOrganizer.
DataOrganizer API
Read the generated split orchestration contract.
Dataset Config
See how dataset entries are written in YAML.
System And Stages
See where dataset creation fits in the overall recipe flow.
DatasetBuilder API
Read the generated lifecycle contract for recipe dataset builders.
BaseRunner API
Read the generated contract for forward, reducer hooks, and merge.
CollectStatsRunner API
Inspect the in-tree reducer-style data pipeline example.